
Outil d’analyse interactive
Introduction
Cet outil en allemand est un complément à logib.admin.ch destiné aux expert-e-s. Il permet d’analyser et de recoder les fonctions avec calcul immédiat de la régression de base (ancien Logib) et de la régression standard de logib.admin.ch, l’équation salariale complète étant indiquée.
Seules les exportations de logib.admin.ch peuvent être importées. Les données recodées peuvent être téléversées sous forme de datalist et réimportées telles quelles dans logib.admin.ch avec les informations correspondantes dans les paramètres d’importation.
Une réinitialisation des données permet de comparer les résultats sans exportation ni réimportation de différents recodages.
La correction Kennedy est indiquée, ainsi que la durée hebdomadaire de travail habituelle calculée (valeur modale) et utilisée pour la standardisation à temps plein (100 %).
Description
L’outil actuel se compose de 6 modules :
- Téléversement,
- Codage des fonctions,
- Diagnostic,
- Funkt-BY,
- Modèles alternatifs. Les modules 1, 2 et 3 présentent la régression standard (y compris deux autres modèles).
- Analyse permettant de filtrer des sous-groupes
La régression standard dans le module 1. Téléversement repose sur les données originales téléversées et n’est pas influencée par les modifications apportées dans les modules 2 et 3, ce qui permet d’effectuer des comparaisons.
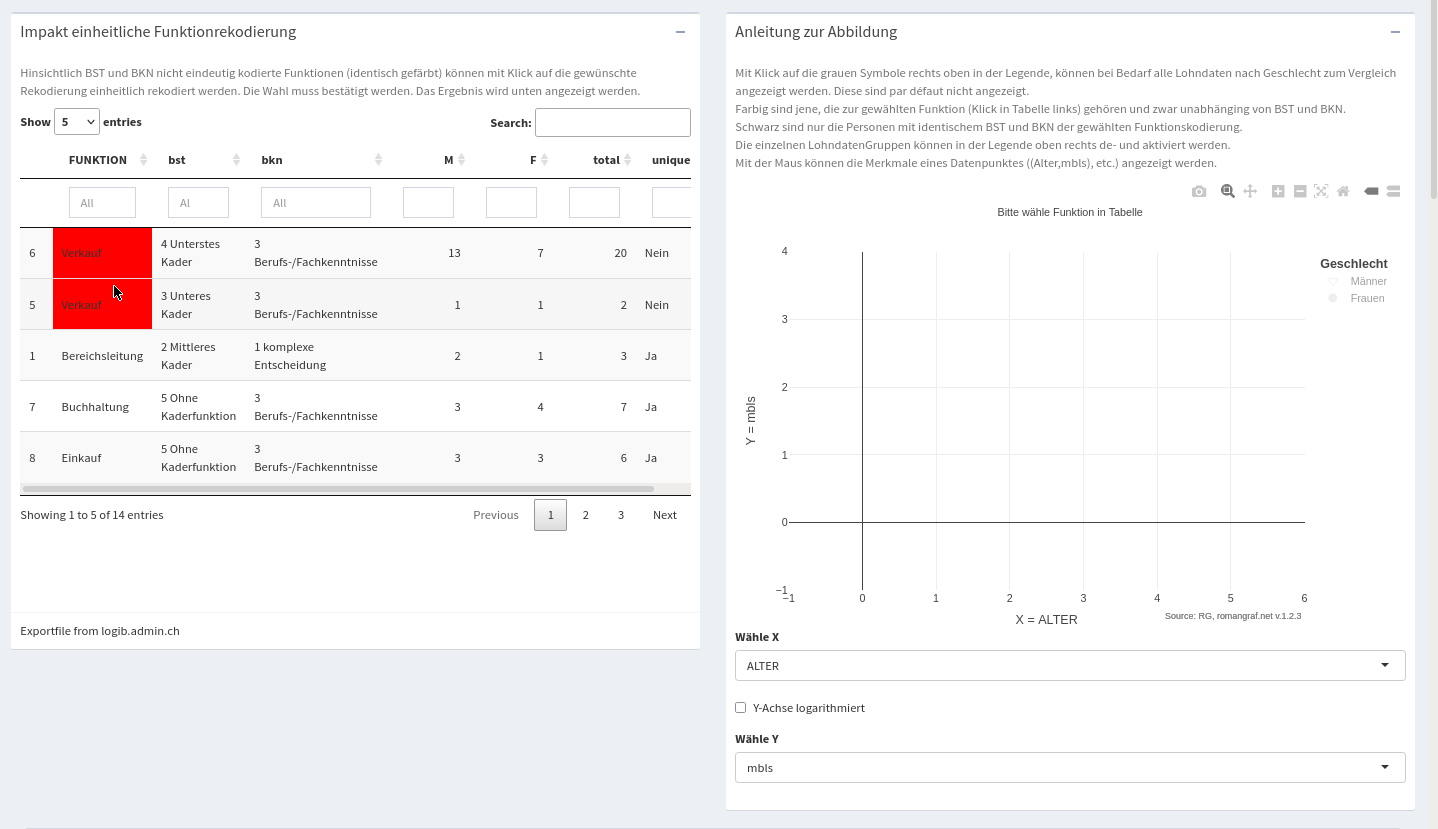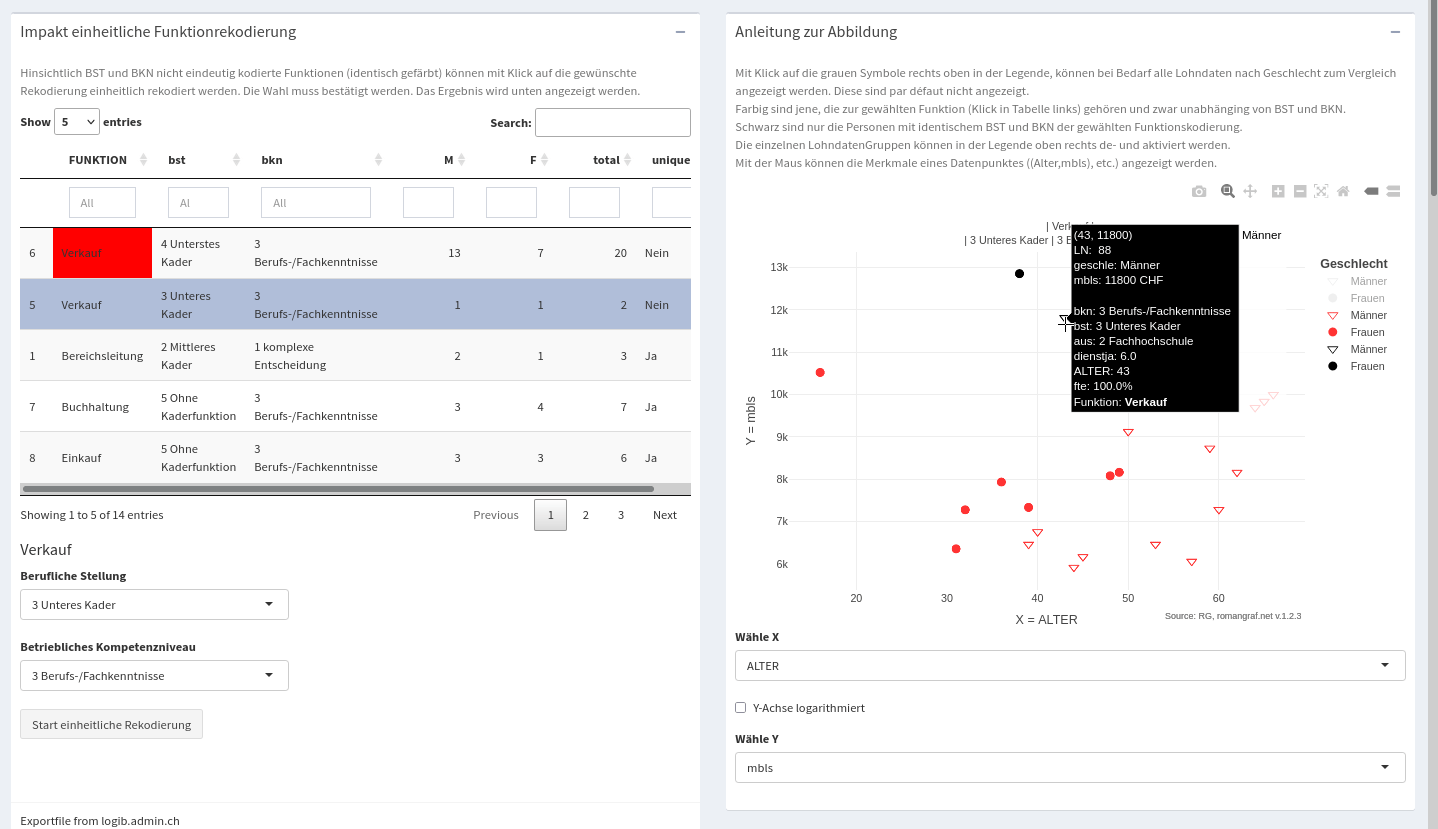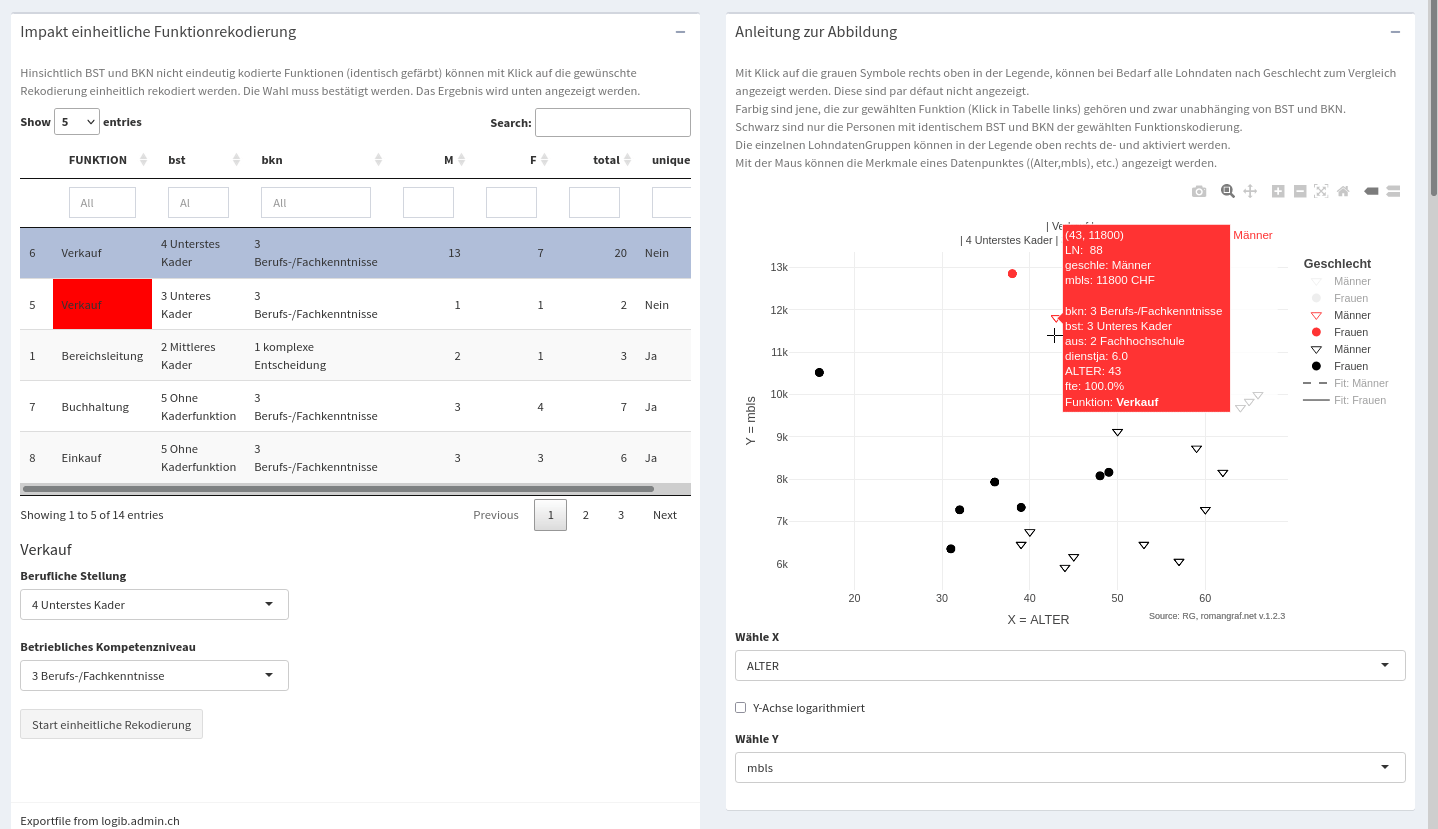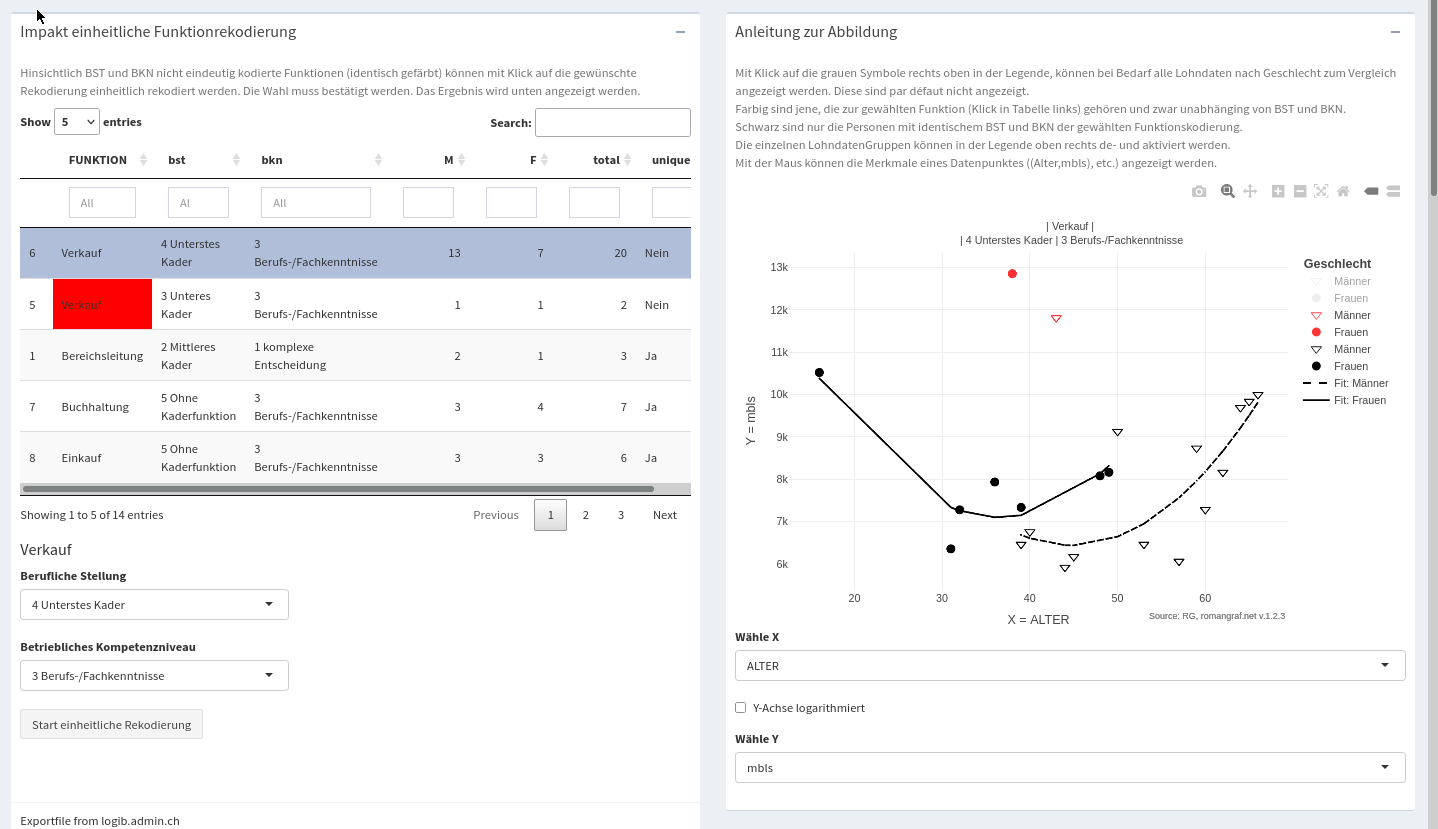
Le module 2. Codage des fonctions permet le recodage uniforme des fonctions ainsi que leur analyse dans un nuage de points avec des variables numériques X et Y sélectionnables.
Les modifications des données dans le module 2 entraînent une mise à jour des données dans les modules 3 à 5. Les exclusions de données dans le module 3 n’ont toutefois aucune influence sur les données enregistrées dans les modules 1, 2, 4 et 5. Ce qui permet la comparaison de 3 états de données différents ou de régressions standard.
Recodage uniforme des fonctions
Le module « Recodage des fonctions » permet le recodage uniforme des fonctions ainsi que leur analyse dans un nuage de points avec des variables numériques X et Y sélectionnables, voir également la description ci-dessous. Après chaque recodage, les résultats sont régénérés (non visibles ici), les données d’origine pouvant être chargées à tout moment à l’aide d’un bouton « Reset ».
Recodage uniforme des fonctions
Vidéo de la régression partielle (voir description de la méthode dans la version 1.2.3 ci-dessous)
Versions
Descripions des versions en allemand …
1.2.6
Einführung von 8 anstelle von 4 Anforderungsniveaus (ohne Anpassung der Anzeige)
1.2.5
zu Ergänzen
1.2.4
Da die die shiny-funktion withMathJax(includeMarkdown(“includeRG.md”)) zur Anzeige von Gleichungen scripts von remote servern einbindet, wird neu direkt html code, der lokal mit pandoc und markdown generiert wird, eingebettet. Somit funktioniert die Anzeige auch off-line.
1.2.3
- 3 Diagnostik, die neue Option 6 Partial regression (lnlohn | others vs geschle | others) erlaubt den Einfluss einzelner Beobachtungen auf den Geschlechter Koeffizienten (Steigung) zu untersuchen, da wichtige Bebachtungen mit Hebelwirkung auf den Koeffizienten graphisch identifiziert werden können und deren Einfluss durch Ausschluss beziffert werden kann (siehe Video oben).
Der Effekt des Geschlechts in der multiplen Regression (Standardregression Logib) ist der Netto-Lohneffekt, wenn für alle anderen Faktoren (others) konntrolliert wird. Anders ausgedrückt: Wenn others bereits ihre Wirkungen entfaltet haben, welchen zusätzlichen, von others linear unabhängigen Einfluss hat dann noch das Geschlecht ? Um dies zu veranschaulichen können zwei Hilfsregressionen 1 und 2 gerechnet werden:
1. \(lnlohn = \beta_0 + \beta_i others + e_{lnlohn}\)
2. \(geschle = \beta_0 + \beta_i others + e_{geschle}\)
3. \(e_{lnlohn}=\beta_1e_{geschle}+e\) (Die Gleichung 3 ist graphisch in der Option 6 dargestellt)
Die Residuen der ersten Regression \(e_{lnlohn}\) sind jene Werte, die durch \(others\) nicht linear erklärt werden können. In diesen Werten ist der Einfluss von \(others\) entfernt oder kontrolliert. (Jedoch nicht jener des Geschlechts)
In der zweiten Regression wird der Einfluss von \(others\) aus dem Prädiktor \(geschlecht\) entfernt. Die Residuen \(e_{geschle}\) enthalten nun Werte, die nicht durch \(others\) linear erklärt werden können.
lnlohn|others vs geschle|others
Um nun die Frage zu beantworten, welchen Nettoeinfluss \(geschle\) auf \(lnlohn\) hat, wird die dritte Regression 3 gerechnet. Die Residuen der ersten Hilfsregression werden auf die Residuen der zweiten Hilfsregression regridiert. Eine Regressionskonstante ist diesmal nicht nötig, da der Mittelwert der Residuen jeweils Null ergibt und die Gerade somit bei P(0,0) durch den Ursprung läuft.
Das heisst, dass nun das um \(others\) bereinigte \(geschle\) den um \(others\) bereinigten \(lnlohn\) voraussagen soll. Der Koeffizient \(\beta_1\) dieser Regression wird partieller Regressionkoeffzient genannt, da er nur jene Teile (Parts) der Beziehung erklärt, an denen \(others\) keinen Anteil mehr hat. Sein Wert ist identisch mit dem Geschlechter Koeffizienten der multiplen Logib-Standardregression.
1.2.2
- 4 Funkt-BY, neu mit Variablenbeschrieb.
- Var Dok Variablenbeschrieb in der Sidebar
- 3 Diagnostik, 4*mean(cook’s D) Linie in Cook’s d vs Leverage Plot
- Behind the scene: Variablenbeschrieb (Abruf in Var Dok und 4 funkt-BY) als list( in vartxt.rds (binary file) für global fast load in global.R gespeichert. Ermöglicht einmaligen load und Zugriff aller Benutzer.
1.2.1
4 Funkt-Quantile wird zu 4 Funkt-BY, weil nicht nur numerische Variablen nach Funktion und Geschlecht als Quantile untersucht werden könnnen, sondern auch die kategoriellen Variablen aus (Ausbildungsniveau), bkn (betriebliches Kompetenzniveau) und bst (berufliche Stellung) und deren Prozentanteile.
1.2
- 5 Alternative Modelle
Die entsprechend genutzten non base Pakete sowie deren Versionen werden auf dem Server dynamisch angegeben. Da die Entwicklungsumgebung nicht gezwungenermassem dieselben Versionen nutzt wie der Prod-Server.
- Doubly Robust
- Abwesenheit eines Geschlechts in einer Merkmalsausprägung (BST,BKN) führt per definition zu NA
- Interaction mit Wahl für Vertrauensintervall (95%) oder Lohngleichung
- Quantil-Regressionen 10%,25%,50%,75%,90%
- rank based Vertrauensintervall nur wenn N<1000, da sehr rechenintensiv.
- Oaxaca-Decompostion (Three-Fold)
- Abwesenheit eines Geschlechts in einer Merkmalsausprägung (BST,BKN) führt per definition zu Abbruch. Muss noch verbessert werden.
Mögliche Verbesserung: dynamischer Aufbau der Methodenwahl nach Datenstruktur.
1.1.4
- 4 Funkt-Quantile
- Ermöglicht Verteilungsanalysen von numerischen Variablen nach Kombinationen Funktion-bkn-bst-geschle.
1.1.3
- 3 Diagnostik
- Punkte und Zonen können neu einzeln oder addiert mit SHIFT+CLICK/SELECT von der Analyse ausgeschlossen werden.
- RESET button für Kein Ausschluss erscheint, wenn Ausschlüsse definiert sind.
1.1.2
- 3 Diagnostik
- Einführung von Marker-Size-Slider
- Ermöglichung partial upate, d.h., die Daten werden bei Slider-Änderungen nicht mehr neu geladen, sondern im Browser (client-side) angepasst. Dies erlaubt ein persistentes Zoomen auch bei Slideränderungen.
1.1.1
- 3 Diagnostik: Abschwächung Plot-Hintergrundfarbe, liniendicke der Symbole erhöht. Einführung Opacitiy-Slider für Erkennung von Datendichten bei vielen Daten. Dieser muss vor dem Zoomen eingestellt werden, da bei Aenderung alle Datenpunkte wieder geladen werden.
Version 1.1
2 Funktionkodierung: Korrektion der Hintergrundfarbe für die gewählten Popup-Information durch Verhinderung von Überlagerungen identischer Punkte (Gesamtsample (Grau) und gewählte Funktionenkodierung (non-unique)).
3 Diagnostik: Abschwächung Plot-Hintergrundfarbe, liniendicke der Symbole erhöht. Einführung Opacitiy-Slider für Erkennung von Datendichten bei vielen Daten. Dieser muss vor dem Zoomen eingestellt werden, da bei Aenderung alle Datenpunkte wieder geladen werden.
Développement interne