Bienvenue sur roman-graf.ch !
Je travaille à la croisée des méthodes en sciences sociales et de l’informatique. Cela me permet d’offrir une large gamme de services en interne.
Parmi ceux-ci figurent:
- La collecte et l’analyse de données
- L’expertise dans le domaine de l’égalité ou de pertes de gain.
- La conception et le développement d’outils interactifs.
L’éthique, l’indépendance et la transparence sont importantes pour moi, cela vaut également pour le choix des technologies.
Merci beaucoup de votre visite.
Je me tiens à votre disposition pour toute question : Contact
Cordialement
Roman Graf

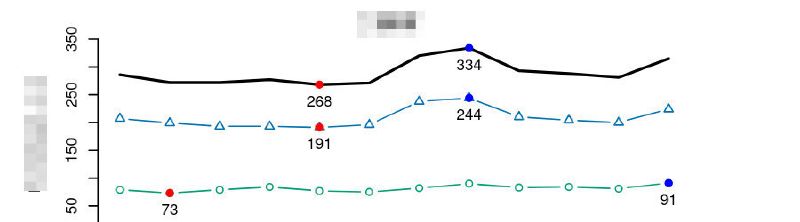
Calcul des salaires en usage
Mandant-e : Secrétariat d’État aux migrations, SEM
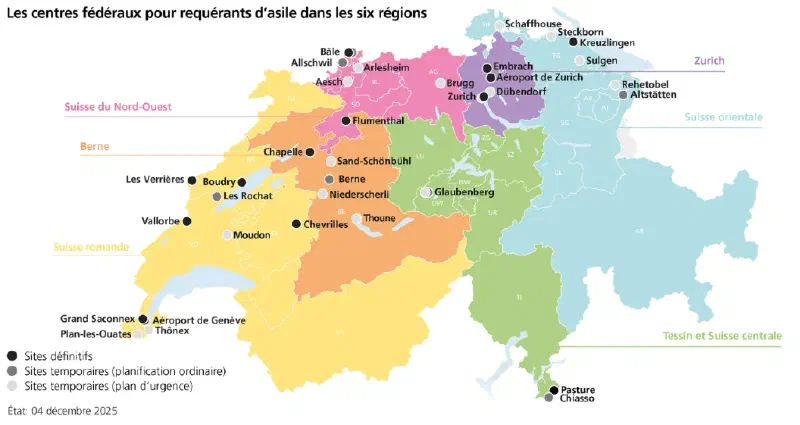
Enquête sur l'emploi dans le secteur biomédical à Genève
Mandant-e : OrTra santé-social genève
Enquête sur la fréquentation des théâtres dans le domaine culturel subventionné et conventionné
Mandant-e : Département de la culture et de la transition, Ville de Genève